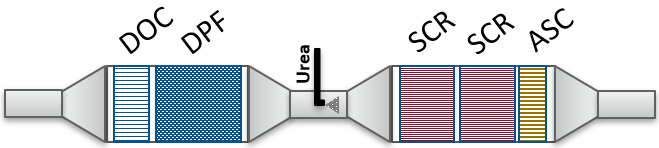
EPA Proposed Amendments to MY 2027+ Heavy-Duty NOx Program
![]()
An overview of EPA’s proposed changes to the Heavy-Duty Low NOx Rule starting MY 2027
The Road Ahead for California’s Vehicle Emission Standards
![]()
An overview of CARBs proposed light- and medium duty “Drive Forward” proposal for MY 2031+ vehicles